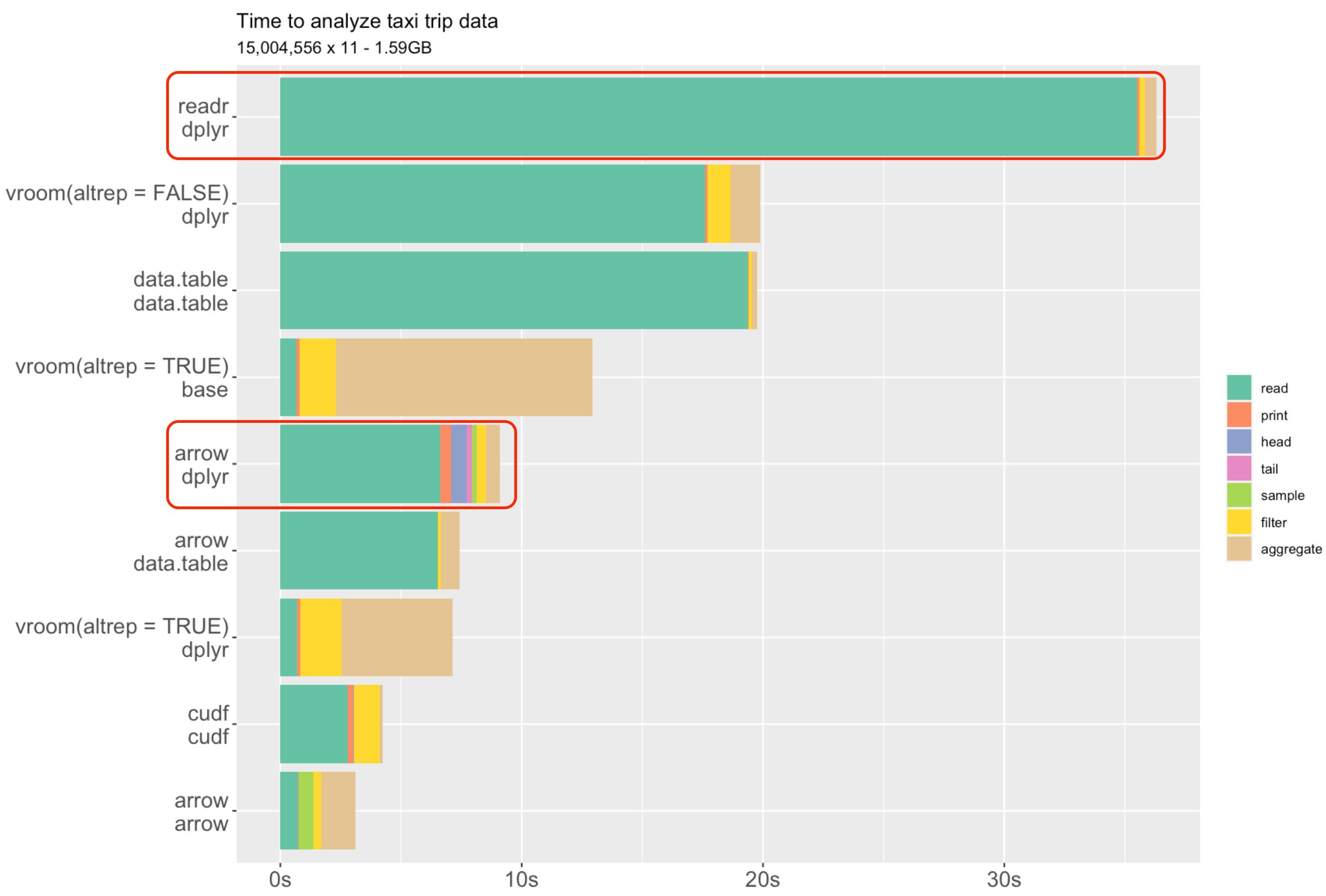
readr::read_lines("./data/murders.csv", n_max = 3) ## there is a header[1] "state,abb,region,population,total" "Alabama,AL,South,4779736,135"
[3] "Alaska,AK,West,710231,19" MATH/COSC 3570 Introduction to Data Science
Which type is the column vector x? Why?
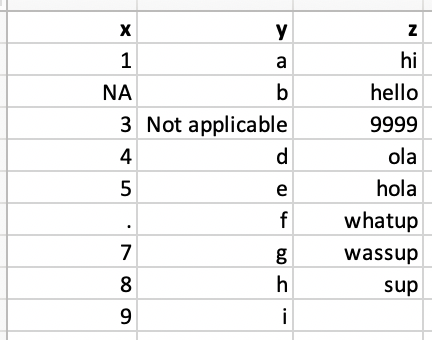
read_csv("./data/df-na.csv")# A tibble: 9 × 3
x y z
<chr> <chr> <chr>
1 1 a hi
2 <NA> b hello
3 3 Not applicable 9999
4 4 d ola
5 5 e hola
6 . f whatup
7 7 g wassup
8 8 h sup
9 9 i <NA> read_csv() only recognizes ” “ and NA as a missing value.na.read_csv("./data/df-na.csv",
na = c("", "NA", ".", "9999", "Not applicable"))
# A tibble: 9 × 3
x y z
<dbl> <chr> <chr>
1 1 a hi
2 NA b hello
3 3 <NA> <NA>
4 4 d ola
5 5 e hola
6 NA f whatup
7 7 g wassup
8 8 h sup
9 9 i <NA>