Frequency Relative Frequency
Heads 4 0.4
Tails 6 0.6
Total 10 1.0
---------------------
Frequency Relative Frequency
Heads 512 0.51
Tails 488 0.49
Total 1000 1.00
---------------------Probability and Statistics 🎲
MATH/COSC 3570 Introduction to Data Science
Probability as Relative Frequency
The probability that some outcome of a process will be obtained is the relative frequency with which that outcome would be obtained if the process were repeated a large number of times.
-
Example:
- toss a coin: probability of getting heads 🪙
- pick a ball (red/blue) in an urn: probability of getting a red ball 🔴 🔵
- If we repeat tossing the coin 10 times, the probability of obtaining heads is 40%.
- If 1000 times, the probability is 51.2%.

Monte Carlo Simulation for Categorical Data
- We get a bag of 5 balls colored in red or blue.
Without peeking at the bag, how do we approximate the probability of getting a red ball?

Monte Carlo Simulation: Repeat drawing a ball at random a large number of times to approximate the probability by the relative frequency of getting a red ball.
So how many red balls in the bag?
Normal (Gaussian) Distribution \(N(\mu, \sigma^2)\)
- Density curve
Draw Random Values from \(N(\mu, \sigma^2)\)
-
rnorm(n, mean, sd): Draw \(n\) observations from a normal distribution with meanmeanand standard deviationsd.
## the default mean = 0 and sd = 1 (standard normal)
rnorm(5)[1] -1.033 0.311 -0.881 0.022 1.657- \(100\) random draws from \(N(0, 1)\)
Histogram of Normal Data (n = 20)
nor_sample <- rnorm(20)
Histogram of Normal Data (n = 200)
nor_sample <- rnorm(200)
Histogram of Normal Data (n = 5000)
nor_sample <- rnorm(5000)
Compute Normal Probabilities
-
dnorm(x, mean, sd)to compute the density value \(f(x)\) (NOT probability) -
pnorm(q, mean, sd)to compute \(P(X \leq q)\) -
pnorm(q, mean, sd, lower.tail = FALSE)to compute \(P(X > q)\) -
pnorm(q2, mean, sd) - pnorm(q1, mean, sd)to compute \(P(q_1\leq X \leq q_2)\)
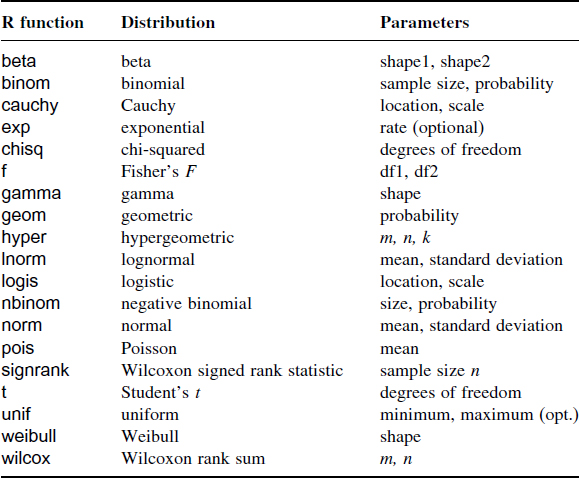
Distributions and Their R Function
Normal Curve
ggplot() +
xlim(-5, 5) +
geom_function(fun = dnorm, args = list(mean = 2, sd = .5), color = "blue")
2. Add geom_col()

Probability vs. Statistics
- Probability : We know the process generating the data and are interested in properties of observations.
- Statistics : We observed the data (sample) and are interested in determining what is the process generating the data (population).
95% Confidence Interval Simulation
\(X_1, \dots, X_n \sim N(\mu, \sigma^2)\) where \(\mu = 120\) and \(\sigma = 5\).
Simulate 100 CIs for \(\mu\) when \(\sigma\) is known
Algorithm
- Generate 100 sampled data of size \(n\): \((x_1^1, x_2^1, \dots, x_n^1), \dots (x_1^{100}, x_2^{100}, \dots, x_n^{100})\), where \(x_i^m \sim N(\mu, \sigma^2)\).
- Obtain 100 sample means \((\overline{x}^1, \dots, \overline{x}^{100})\).
- For each \(m = 1, 2, \dots, 100\), compute the corresponding confidence interval \[\left(\overline{x}^m - z_{\alpha/2} \frac{\sigma}{\sqrt{n}}, \overline{x}^m + z_{\alpha/2}\frac{\sigma}{\sqrt{n}}\right)\]

mu <- 120; sig <- 5
al <- 0.05; M <- 100; n <- 16
set.seed(2026)
x_rep <- replicate(M, rnorm(n, mu, sig))
xbar_rep <- apply(x_rep, 2, mean)
E <- qnorm(p = 1 - al / 2) * sig / sqrt(n)
ci_lwr <- xbar_rep - E
ci_upr <- xbar_rep + E
plot(NULL, xlim = range(c(ci_lwr, ci_upr)), ylim = c(0, 100),
xlab = "95% CI", ylab = "Sample", las = 1)
mu_out <- (mu < ci_lwr | mu > ci_upr)
segments(x0 = ci_lwr, y0 = 1:M, x1 = ci_upr, col = "navy", lwd = 2)
segments(x0 = ci_lwr[mu_out], y0 = (1:M)[mu_out], x1 = ci_upr[mu_out], col = 2, lwd = 2)
abline(v = mu, col = "#FFCC00", lwd = 2)![]()

Normal Curve Plotting
import matplotlib.pyplot as pltmu = 100
sig = 15
x = np.arange(-4, 4, 0.1) * sig + mu
hx = norm.pdf(x, mu, sig)
plt.plot(x, hx)
plt.xlabel('x')
plt.ylabel('density')
plt.title('N(100, 15^2)')
plt.show()